{kind=link}
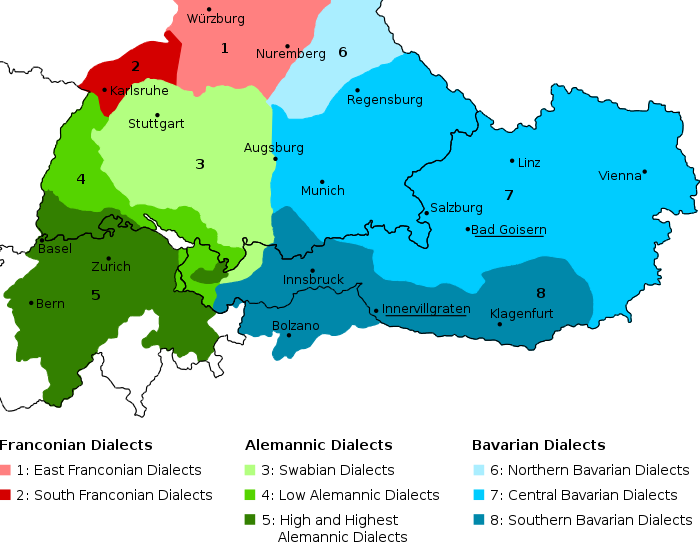
The GIDS Goisern and Innervillgraten Dialect Seech Corpus is a collection of audiovisual speech recordings for research purposes. It consists of a total of 7068 sentences spoken by eights speakers from two Austrian towns, Bad Goisern and Innervillgraten. For each speaker, about two thirds of the recorded sentences are in the speaker's respective dialect and the rest is in Standard Austrian German. The dialect of Bad Goisern in the Salzkammergut region belongs to the Central Bavarian dialect family, and the dialect of Innervillgraten in the East Tyrol region belongs to the Southern Bavarian dialect family, as illustrated below (image based on http://commons.wikimedia.org/wiki/File:Oberdeutsche_Dialekte.png).
The following table gives the number of recorded sentences for each speaker.
| Speaker | Dialect | Gender | Dialect Sentences | Standard Sentences |
|---|---|---|---|---|
| 1 | Bad Goisern | female | 665 | 223 |
| 2 | Bad Goisern | female | 665 | 223 |
| 3 | Bad Goisern | male | 665 | 223 |
| 4 | Bad Goisern | male | 665 | 223 |
| 5 | Innervillgraten | female | 656 | 223 |
| 6 | Innervillgraten | female | 656 | 223 |
| 7 | Innervillgraten | male | 656 | 223 |
| 8 | Innervillgraten | male | 656 | 223 |
The recordings consist of optical 3D facial motion tracking data, captured with a NaturalPoint OptiTrack Expression system, the greyscale video data also recorded by the same system, and studio quality audio.
There is no dedicated publication for this corpus, however it is mentioned in the PhD dissertation of Dietmar Schabus (PDF, bibtex) and in this article:
This open access article can be obtained via http://dx.doi.org/10.1109/JSTSP.2013.2281036. Please cite this article if you use the corpus for your research.
There are two related corpora, the MMASCS corpus and the FMSC corpus, for each of which a corresponding LREC conference paper exists (paper 1, paper 2). Some of the information in these papers is relevant also for the GIDS corpus.
For each of the recorded utterances, the corpus contains:
The data can be obtained free of charge for scientific research purposes (see the license). Contact Michael Pucher (michael.pucher@oeaw.ac.at) if you would like to obtain a copy.
The GIDS corpus was created in the research project Adaptive Audio-Visual Dialect Speech Synthesis (AVDS), funded by the Austrian Science Fund (FWF) under the project number P22890-N23. This project was coordinated by the Telecommunications Research Center Vienna (FTW). The Competence Center "FTW Forschungszentrum Telekommunikation Wien GmbH" is funded within the program COMET Competence Centers for Excellent Technologies by BMVIT, BMWFW and the City of Vienna. The COMET program is managed by the FFG.
The recordings were carried out in the premises of the Acoustics Research Institute of the Austrian Academy of Sciences.
Michael Pucher (michael.pucher@tugraz.at)